Improve Retrieval Augmented Generation Through Classification

Retrieval augmented generation, or RAG, is a technique used to provide custom data to an LLM in order to allow the LLM to answer queries about data on which it was not trained. When building a custom LLM solution, RAG is typically the easiest and most cost-effective approach. However, the quality of response from an LLM customized using RAG is heavily dependent on the quality of the system message and data provided alongside the queries. In order to improve the quality of retrieval augmented generation responses, we can use classification to select better data and system messages to augment queries.
Consider, for example, the query “Should I invest in Company Foo?” and a typical RAG system message like “You are a friendly AI; answer queries using the data appended below,” followed by investment data about the company. This query may give poor results because the system message restricts the LLM from answering using only the data provided, and the data provided contains no information about how to define a good investment. We need a system message like “You are an AI helping to make investment decisions. Use the data appended below to help answer queries” or something similar, removing the restriction to only use the appended data. Unfortunately, however, such a system message will break any non-investment queries that users make.
Similar issues exist when fetching data to append to the system message. A query about investment might want to access news articles about a company, while a query about what hours a company is open might want to access an FAQ page. We can, of course, place all this data in the same search engine, but a search engine can give sub-optimal results to queries like “What information is available to investors?” if the FAQ page also happens to contain this question but just links to another page. To get better results, we’d be better off explicitly searching our investor information pages rather than using a generic search engine.
To resolve the above issues, we can use multiple system messages and multiple data sources to provide better results across a wider range of queries. We can do this by analyzing queries in order to determine the system message to use or data to access on a per-query basis. This is done using the LLM to perform classification, separating queries into different types. Each query type can then have its own system message or source data set, greatly improving query results over the generic case.
Improving Retrieval Automated Generation With Multiple System Messages
Let us consider an example of a custom LLM that we want to use to respond to queries from both our technical writing and SEO teams. We want to handle technical writing queries like “Write a short summary of our widget product page” and queries from our SEO team like “What can I do to improve the SEO of the widget product page?”. Let’s assume that we have a search engine that returns the widget product page when these queries are made and provides the page contents to the LLM when these queries are run. What sort of system message can we select to improve the retrieval augmented generation results in both these cases?
In a typical RAG implementation, we would use a system message similar to “You are a helpful AI. Use the information provided below to answer any queries you are given. If the query cannot be answered using the information provided below, tell the user you do not know the answer. Do not guess.” This would then be followed by the contents of the page returned by the search engine.
This type of system message works well for our example technical writer query, but it performs poorly for the SEO query. This is because the provided information will not contain any information about SEO, and so the AI will often respond that it does not know the answer. We know that the LLM understands SEO and can perform this analysis, but this standard RAG system message greatly limits the flexibility of the LLM’s responses.
Unfortunately for us, this limitation is exactly what we want when answering queries from our technical writers. We need the LLM to avoid hallucinating incorrect answers when asked to create summaries, so we can not use a system message that gives the LLM any leeway.

One solution to this problem is to use different system messages for queries made by different types of users. Initially, we could handle this by providing a different UI for both of these types of users, but this approach does not scale well. As we need to support increasing types of users, we will have to create an increasing number of UIs or provide some sort of menu and rely on our users to correctly select their use cases.
A more scalable approach to improve our RAG process is to use classification to determine what system message works best for a specific query. A first naive classification might be to classify any query containing the keyword “SEO” as an SEO query and then use the SEO system message instead of the helpful AI system message, but this can lead to some challenges. We can easily imagine a technical writing task asking us to summarize some work done by the SEO team with a query like “Please summarize the SEO widget page brainstorming session,” which would break this naive classifier.
Classifying RAG Queries Using an LLM
Instead of trying to naively classify queries using direct analysis and word matching, we can leverage our LLM to perform the classification for us. We do this by creating a separate request to the LLM asking it what user would be best at answering a specific query and providing it a list of users it can pick from.
For example, we could use the following system message: “You are an AI helping to determine who best can answer a specific question. You must pick either an SEO specialist or technical writer. Answer only with the one you think can best answer the question”. Then, when we pass the user’s query, the response is from either an SEO specialist or a technical writer. We then select the correct system message for the query type and pass the user’s query with the correct system message to get a final response from the LLM.
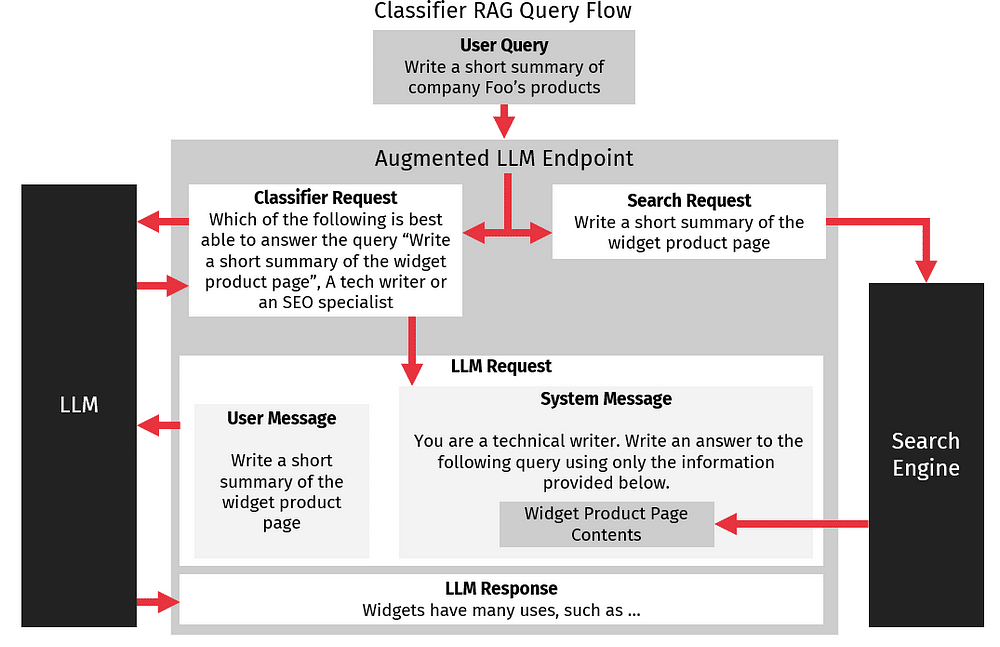
This classification leveraging the LLM works surprisingly well. LLMs are naturally good at this type of word-based classification because LLMs store information about words and their relationships to one another. This means an LLM can quite accurately predict what type of thing is most similar to another thing, and query classification is essentially this type of problem. Using classification to automatically select a system message will allow use to choose better system messages which will improve retrieval augmented generation query results.
Using Classification To Support Multiple Data Stores
Similar to how query classification can be used to determine what system message can be used, we can also leverage classification to determine what data source should be used, allowing us to leverage multiple data sources to improve retrieval augmented generation queries. To extend our earlier example, we might have multiple internal data sources which our technical writers need to create summaries from. For example, we may have a company wiki containing information about v2 widgets and a legacy document store containing information about v1 widgets.
Rather than trying to combine these two sources of knowledge together, requiring us to create a third document store that aggregates data from these two sources, we can instead analyze queries and determine which of these stores makes the most sense to use, perhaps classifying queries based on if they need information about v1 or v2 widgets. We might even provide a third classification for queries that require information about both types of widgets, accessing both data stores for information to augment our queries.
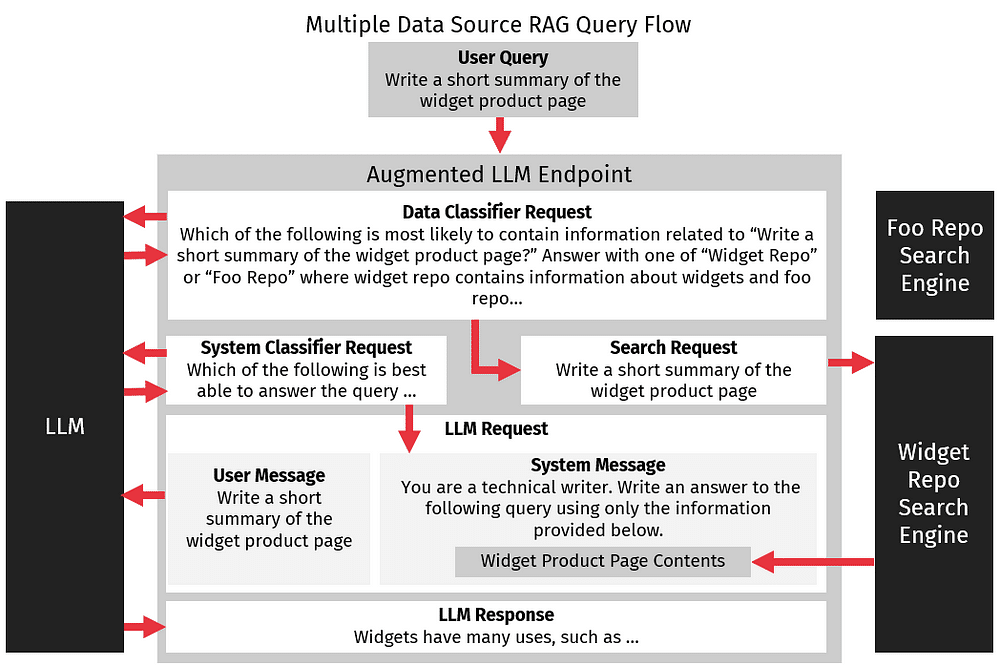
In the above example, we may consider always querying both our legacy and wiki systems but consider the performance and computational costs. For example, querying our legacy system could be quite slow, or there could be cloud costs associated with querying our wiki. We can improve our performance and reduce costs by using classification to simplify our querying process.
Improve Retrieval Automated Generation Using Real-Time Data
We can further extend our support for multiple data sources by querying for real-time data using a data source that supports real-time insertion and querying. Typically, with RAG, we should avoid real-time data in favor of data that is well-indexed since the search speed impact of querying a real-time data source is quite high. However, if we can minimize interactions with the real-time data source, the overhead of searching it occasionally may be acceptable. Furthermore, search engine indexing is typically a batched process run at regular intervals on a small set of new documents. If we can determine the data we need is likely to be unindexed, we may be able to directly search this unindexed data if it is small enough, and with our RAG supporting multiple data sources, we can choose to search this unindexed data if needed.
Retrieval Augmented Generation Is Easily Improved With Classification
RAG is a powerful, cost-effective, and easily implemented way to customize LLMs, but its results are heavily dependent on the system message and the retrieved data passed with the query. We can greatly improve both the results and reliability of retrieval augmented generation by selecting the best system message and data source, and we can leverage our LLM to help us select from a preconfigured list of both. LLMs are naturally good at this type of classification task, meaning we can expect a high degree of accuracy during classification, and when the system message and retrieved data are highly supportive of our original query, our LLM can give stronger and more accurate results to user queries.
Are you building a solution using cloud infrastructure? Learn more about how to automate your infrastructure deployments in our previous blog post, or contact us for more information.
References
What is Retrieval Augmented-Generation, aka RAG? https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
Retrieval augmented generation: Keeping LLMs relevant and current https://stackoverflow.blog/2023/10/18/retrieval-augmented-generation-keeping-llms-relevant-and-current/
